Aperçu
1. Architecture matérielle
Un ordinateur réalise 2 fonctions principales :
-
stocker des programmes et des données,
-
les traiter.
Il est donc logiquement composé d’unités de traitement (les CPU) et d’unités de stockage (la mémoire).
1.1. RAM
La RAM, ou mémoire vive, est volatile. Elle mémorise données et programmes. Sa taille est en 2020 de quelques dizaines ou centaines de Go (typiquement 2 Go pour un smartphone, 16 Go pour un poste de travail, 256 Go pour un serveur). Son accès est rapide : cela signifie qu’une information recherchée est rapidement localisée. Son taux de transfert est rapide : cela signifie que récupérer ou y déposer des données est rapide. Comme la RAM est volatile, pour conserver les données et les programmes sans énergie, ceux-ci doivent être déplacés vers de la mémoire non volatile (disque, clé USB, etc.), située en périphérie de l’ordinateur, donc d’accès et de transfert beaucoup plus lent (mais de capacité plus importante).
1.2. CPU
Le CPU, ou processeur, est le cerveau de l’ordinateur. Il séquence, décode et exécute les instructions d’une part, effectue les calculs d’autre part. Il se compose d’une unité de traitement pour l’exécution des programmes, d’une unité arithmétique et logique pour le calcul entier (ALU) et d’une unité flottante pour le calcul flottant (FPU). Ces unités de calcul travaillent sur des registres : données et instructions doivent être déposées dans ces registres pour pouvoir être manipulées. Un registre est une mémoire élémentaire, de la taille d’un entier dans l’ALU et d’un flottant dans le FPU. C’est une mémoire de transit : les données et instructions migrent de la RAM vers les registres en vue d’être traitées, et les résultats, obtenus dans les registres, sont déplacés à leur tour en RAM pour laisser place nette (pour les prochains calculs).
Le CPU possède également une file d’instructions à exécuter, et un pointeur vers la prochaine instruction à exécuter : le compteur ordinal.
2. Tâche
Une tâche (ou processus) est une instance de programme ou de sous-programme (c’est-à-dire un programme ou sous-programme en cours d’exécution).
Par exemple, soit :
def f(x): return [ (i,i**2) for i in x ]
alors f(range(1,100,3)) et f([]) sont 2 tâches, instances d’un même sous-programme f(x).
Une tâche se compose d’instructions et du contexte dans lequel elle évolue : ses variables, la pile des appels de fonctions, le pointeur vers l’instruction en cours d’exécution, etc. Elle n’a pas d’existence hors de ce contexte : suspendre, reprendre ou déplacer une tâche suppose de sauvegarder et de restaurer son contexte.
Dans l’exemple précédent,
suspendre l’une des tâches nécessite, si on veut pouvoir la poursuivre plus tard, de sauvegarder les instructions, l’adresse de la prochaine à exécuter (le compteur ordinal),
les variables i et x et la liste en construction.
2.1. Système multi-tâche
C’est un système informatique capable de gérer l’exécution de plusieurs tâches en même temps.
| Cette caractéristique n’est pas liée au nombre de CPU sous-jacents : un système multi-tâche peut tourner sur une architecture mono-CPU. Dans ce cas, la simultanéité apparente est le résultat de l’alternance rapide et l’entrelacement des tâches. |
top visualise l’exécution des taches d’un système Unix$ top
top - 08:50:57 up 19 days, 53 min, 2 users, load average: 1,35, 1,23, 1,02
Tasks: 286 total, 1 running, 285 sleeping, 0 stopped, 0 zombie
%Cpu(s): 5,0 us, 6,2 sy, 0,0 ni, 87,5 id, 0,0 wa, 1,2 hi, 0,0 si, 0,0 st
MiB Mem : 7601,4 total, 165,6 free, 6130,6 used, 1305,2 buff/cache
MiB Swap: 7760,0 total, 1675,1 free, 6084,9 used. 360,9 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1037125 jaclin 20 0 9520008 3,4g 28632 S 10,5 45,6 41:06.08 thunder+
1762370 jaclin 20 0 227620 4380 3636 R 10,5 0,1 0:00.04 top
1 root 20 0 177148 7976 3420 S 0,0 0,1 1:02.41 systemd
2 root 20 0 0 0 0 S 0,0 0,0 0:01.40 kthreadd
3 root 0 -20 0 0 0 I 0,0 0,0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0,0 0,0 0:00.00 rcu_par+
6 root 0 -20 0 0 0 I 0,0 0,0 0:00.00 kworker+$ sleep 5 ; echo fini # 2 tâches en série
$ sleep 5 & echo fini # 2 tâches en parallèle
$ (sleep 5 ; echo fini1) & echo fini2
$ sleep 10 & # tâche en arrière plan (background)
$ jobs # liste des tâches
$ ( sleep 15 ; echo fini 15 ) & # tâche de fond #1
$ ( sleep 10 ; echo fini 10 ) & # tâche de fond #2
$ jobs # liste des tâches
$ time sleep 100 &
$ kill %1 # destruction d'une tâche de fond$ find / -name notfound.txt # foreground
$ ^Z # tâche mise en pause
$ jobs
$ bg # tâche passée en background
$ fg # tâche passée en foreground2.2. Communication entre processus
2 processus peuvent échanger de l’information de 2 façons : soit au travers de variables partagées, soit par envois de messages.
Le partage de variables entre processus nécessite une mémoire commune accessibles aux processus. La communication par messages peut être, quant à elle, synchrone ou asynchrone.
Dans une communication synchrone, l’émetteur et le récepteur se donnent rendez-vous, pour échanger de l’information. Dans une communication asynchrone, l’émetteur poursuit son exécution après avoir envoyé son message, sans se soucier du récepteur qui en prendra connaissance quand il voudra ou quand il le pourra.
|
Analogie
Le téléphone est un mode de communication synchone (la boîte vocale vise à le rendre asynchrone).
Le mail est un mode de communication asynchrone.
|
2.3. Interaction de 2 processus : la synchronisation
2 processus sont synchronisés si leur exécution respective est liée. Cela implique que les processus puissent échanger de l’information (de contrôle) entre eux. Par exemple, si un processus A dépend de données produites par un processus B, alors A doit pouvoir attendre que les données soient disponibles.
2.4. Gestion du multi-tâche
Le système doit gérer un ensemble de tâches en les faisant progresser équitablement (mais il peut y avoir un système de priorités). Il lance l’exécution de la 1ère, et passe à la seconde avant que la première soit terminée : l’exécution des tâches se fait donc par parties. Ces exécutions morcellées et entrelacées donnent l’illusion que toutes les tâches sont exécutées en même temps, alors qu’elles s’exécutent les unes après les autres sur des temps courts (1 CPU ne peut exécuter qu’une instruction à la fois).
Passer d’une tâche à une autre (commutation de tâches) consiste à :
-
sauvegarder le contexte de la tâche à interrompre (le code, les variables, le compteur ordinal, la pile des appels de fonctions en cours, etc.), la suspendre et libérer les ressources qu’elle utilisait,
-
restaurer le contexte de la tâche à ressusciter, et reprendre son exécution à l’endoit où elle s’était interrompue.
|
Analogie
Les simultanées de Kasparov.
|
Le choix de la tâche à exécuter parmi l’ensemble des tâches en attente dépend de la stratégie d’ordonancement du système, comme par exemple, choisir parmi les tâches suspendues celle qui attend depuis le plus longtemps.
Cette commutation de contextes a un coût : on peut arriver à la situation paradoxale où le temps passé à commuter les contextes est supérieur au temps attribué aux tâches.
- swap
-
Il arrive parfois que les contextes sauvegardés soient si volumineux qu’ils ne tiennent pas en RAM. Dans ce cas, le système en déplace certains dans un espace plus volumineux (mais moins rapide) sur disque, suivant une stratégie prédéterminée : par exemple, en déplaçant les moins utilisés, ou bien les plus volumineux, ou bien les endormis depuis longtemps, etc. Cet espace de stockage de secours est appelé swap (ou, sous Windows, fichier d’échange). C’est pourquoi une machine surchargée par un trop grand nombre de tâches sollicite à outrance son disque : elle transfert les contextes de la RAM à la swap, et inversement. On dit alors que le système swappe. Il n’est pas rare que le phénomène s’emballe, conduisant une à congestion du système, dont le reboot est la seule issue.
La commutation peut être à l’initiative de la tâche en cours d’exécution elle-même (multitâche coopératif) ou bien par le système (multitâche préemptif).
2.4.1. Multitâche coopératif
C’est une forme de multitâche, où chaque tâche doit explicitement permettre aux autres de s’exécuter. C’est ainsi que fonctionnent Microsoft Windows (1987) jusqu’à la version 3.11, Mac Système 7 (1991), ainsi que les coroutines de Python. Les tâches décident elles-mêmes du moment où elles passent la main. C’est donc au programmeur de la tâche de gérer le multi-tâche. Avantage : il en a la maitrise, il n’y a pas de surprise possible pour lui. Inconvénient : c’est du travail supplémentaire pour lui.
S’il est plus simple du point de vue du système, le multitâche coopératif présente quand-même quelques défauts. Il fonctionne bien à condition que toutes les tâches respectent les règles. Il suffit d’une tâche qui ne joue pas le jeu pour qu’elle accapare la scène sans risque d’être interrompue. Par exemple, une tâche qui entre dans une boucle infinie peut paralyser le système et toutes les tâches en cours. La fluidité des traitements et l’équité des chances pour accéder aux ressources (temps CPU, mémoire, accès disque, etc.) dépendent de la façon dont chaque tâche rend périodiquement la main. Le système est donc incapable de garantir une efficacité, ni même une stabilité de fonctionnement.
2.4.2. Multitâche préemptif
Dans cette forme de multitâche, le système lui-même donne la main aux tâches, et la reprend tout aussi autoritairement. C’est le mode de fonctionnement d’Unix (1969), de Microsoft Windows NT (1991) et suivant, et de MacOSX (2001). Chaque tâche est périodiquement suspendue pour permettre aux autres d’avancer. Pour cela, le système sauvegarde la tâche à suspendre (c’est-à-dire libère les ressources qu’elle utilise, après avoir sauvegardé son contexte), puis choisit une autre tâche en attente, restaure son contexte, et lui redonne la main pour un petit moment.
Le multitâche préemptif est plus robuste que le multitâche coopératif :
une tâche ne peut pas bloquer l’ensemble du système,
le système connait toutes les tâches,
et il peut toujours se débarasser (kill) d’une tâche défectueuse.
Par rapport au multitâche coopératif, vue des tâches préemptées, la commutation est transparente :
le programmeur n’a rien à faire, il ne la voit même pas dans son code
(en revanche, vue du système, la gestion est plus complexe).
Mais cette préemption peut arriver n’importe quand, ce qui peut poser d’autres problèmes.
2.5. Accès concurrents
Plusieurs tâches peuvent vouloir accéder en même temps à une même ressource : la mémoire, le clavier, l’écran, l’imprimante, la carte son, la webcam, le micro.
| Exemple d’accès concurrent dans la vie de tous les jours : 2 personnes réservant par Internet en même temps, sur un même vol, la dernière place. A un moment donné au cours de la transaction, l’une des 2 réservations va échouer, et, au final, seule une personne pourra prendre l’avion. |
Le code ci-dessous illustre des accès concurrents à la mémoire.
Soit y une variable globale, x une variable locale, et f() une fonction
qui incrémente la variable globale y en utilisant une variable intermédiaire x :
y = 1
def f():
x = y
x += 1
y = x
f() # y vaut 2Si l’on exécute 2 instances de f, on s’attend à ce que y soit incrémenté 2 fois
(c’est-à-dire que y vaille 3).
Et c’est en effet ce que l’on obtiendrait avec 2 exécutions successives.
Si les 2 exécutions sont concurrentes (avec un multi-tâche préemptif),
on peut obtenir le séquencement suivant :
y = 1 y:1
[tâche A] [tâche B]
x = y y:1, A.x:1
x += 1 y:1, A.x:2
y = x y:2, A.x:2
x = y y:2, A.x:2, B.x:2
x += 1 y:2, A.x:2, B.x:3
y = x y:3, A.x:2, B.x:3
qui conduit au même résultat : y vaut 3.
Mais ce n’est pas systématique :
y = 1 y:1
[tâche A] [tâche B]
x = y y:1, A.x:1,
x = y y:1, A.x:1, B.x:1
x += 1 y:1, A.x:2, B.x:1
x += 1 y:1, A.x:2, B.x:2
y = x y:2, A.x:2, B.x:2
y = x y:2, B.x:2, B.x:2
ici y vaut 2, ce n’est plus le résultat intuité.
Le résultat de l’exécution concurrente de plusieurs instances de f est donc indéterminé, il dépend du séquencement des instructions.
| Une fonction est dite réentrante si l’exécution concurrente de ses instances est déterministe, c’est-à-dire donne toujours le même résultat. |
f n’est donc pas réentrante.
Et cela est dû au fait que :
-
yest partagée (c’est une variable globale) -
sa modification n’étant pas atomique (3 instructions réalisent l’incrémentation), des interférences peuvent se produire entre le début et la fin (de l’incrémentation).
2.6. Section critique
On supprime l’indéterminisme de l’exemple précédent en rendant l’incrémentation ininterruptible :
def f():
v.lock()
x = y
x += 1
y = x
v.unlock()v est un verrou, c’est-à-dire un objet à 2 états (ouvert/fermé)
et doté de 2 méthodes lock et unlock qui le font changer d’état :
-
lock()ferme le verrou, si le verrou est ouvert. Si le verrou est déjà fermé, alorslock()attend qu’il s’ouvre, puis le referme. Cette attente suspend l’exécution de la tâche -
unlock()ouvre le verrou (ce qui peut débloquer du même coup une attente).
Ce qui donne par exemple :
y = 1
[tâche A] [tâche B]
v.lock() demande de fermeture : verrou fermé par A
v.lock() demande de fermeture : attente de B
x = y
x += 1
y = x
v.unlock() ouverture par A : déblocage de B et fermeture par B
x = y
x += 1
y = x
v.unlock() ouverture par B
ou bien :
y = 1
[tâche A] [tâche B] [v]
lock() fermé par B
x = y
x += 1
lock() fermé, A attend pour le fermer à son tour
y = x
unlock() ouvert par B, puis fermé par A
x = y fermé
x += 1
y = x
unlock() ouvert
et y vaut maintenant 3 à tous les coups.
Le bloc d’instructions protégé par le verrou s’appelle une section critique. Par définition, c’est une portion de code qui doit être traitée comme une instruction atomique (on peut faire l’analogie avec la notion de transactions dans les SGBD).
2.6.1. Ensemble de sections critiques
La section critique permet donc de gérer correctement les accès concurrents à une ressource donnée. Si ces accès apparaissent à plusieurs endroits dans le code, ils devront être protégés de la même façon (avec le même verrou). On obtient alors un ensemble de sections critiques relatif à la protection d’une ressource donnée.
Dans un programme, il y a autant d’ensembles de sections critiques qu’il y a de ressource à protéger.
Toutes les sections critiques d’un même ensemble sont mutuellement exclusives :
leurs exécutions ne peuvent pas se superposer.
Par contre, l’exécution simultanée de sections critiques appartenant à des ensembles différents
est possible.
Dans l’exemple suivant, on a 2 variables globales partagées a et b,
modifiées à 3 endroits dans le programme,
donc
3 sections critiques réparties en 2 ensembles (correspondant à 2 verrous v1 et v2) :
# section critique 1 protégeant l'accès en écriture à a
v1.lock()
x = a
x += 1
a = x
v1.unlock()
...
# section critique 2 protégeant l'accès en écriture à b
v2.lock()
y = b
y *= 2
b = y
v2.unlock()
...
# section critique 3 protégeant l'accès en écriture à a
v1.lock()
z = a
if (z<0):
z = 0
a = z
v1.unlock()2.6.2. Exclusion mutuelle
L’exécution d’une section critique ne peut commencer que si aucune autre section critique du même ensemble n’est en cours d’exécution. Pour qu’un système fonctionne correctement, sa gestion des exclusions mutuelles doit assurer quelques bonnes propriétés :
-
au plus un seul processus exécute une section critique d’un ensemble donné
-
un processus en attente d’entrer dans une section critique doit pouvoir le faire le moment venu sans qu’un processus nouveau venu lui passe sous le nez (équité)
-
un processus souhaitant entrer en section critique doit y entrer au bout d’un temps fini (pas de famine)
-
si le processus en section critique disparait inopinément (crash, kill), le système ne doit pas resté bloqué (tolérance aux pannes)
|
Généralisation
Le problème de l’accès critique de n processus à m ressources identiques (par exemple un pool d’imprimantes)
peut se traiter avec des sémaphores (Dijkstra, 1965).
|
2.7. Inter-blocage
L’utilisation des sections critiques doit se faire avec précaution.
Dans l’exemple suivant, on a 2 variables globales partagées g1 et g2,
une fonction f() qui permute g1 et g2,
et une fonction g() qui ajoute g2 à g1 et soustrait g1 à g2.
Les modifications de g1 sont protégées par un verrou v1,
et de même, les modifications de g2 sont protégées par un verrou v2 :
g1 = 1
g2 = 2
def f():
v1.lock()
v2.lock()
x = g1
g1 = g2
g2 = x
v2.unlock()
v1.unlock()
def g():
v2.lock()
v1.lock()
x = g1+g2
y = g2-g1
g2 = y
g1 = x
v1.unlock()
v2.unlock()L’exécution concurrente de f() et g() peut se trouver séquencée comme :
f g
v1.lock() demande de fermeture de v1 par f : v1 fermé
....
v2.lock() demande de fermeture de v2 par g : v2 fermé
v1.lock() demande de fermeture de v1 par g : attente
....
v2.lock() demande de fermeture de v2 par f : attente
....
et là, la situation est définitivement bloquée. Cette situation d’inter-blocage est appelée étreinte fatale ou deadlock.
3. Parallélisme
Le parallélisme caractérise l’exécution simultanée d’instructions. Deux instructions s’exécutent en parallèle si elles se superposent dans le temps. Le but du parallélisme est de réduire le temps d’obtention d’un résultat.
Le parallélisme est apparu dans les années 1970 au travers de machines spécifiques telles que les calculateurs vectoriels (Cray-1, 1976). En 2020, le moindre smartphone est multi-coeurs.
Le parallélisme permet de réaliser toujours plus de tâches en toujours moins de temps, sans accroître la fréquence de traitement (qui augmenterait la température et la consommation d’énergie).
3.1. Architecture parallèle
C’est un matériel capable d’exécuter plusieurs instructions pendant le même intervalle de temps. Une architecture parallèle possède donc plusieurs unités de traitements.
3.1.1. Ordinateur multiprocesseur
C’est un ordinateur avec plusieurs CPU (de deux à plusieurs milliers dans les architectures massivement parallèles). Le but est d’accroitre la puissance de traitement. Il n’existe pas d’architecture unique pour ce type d’ordinateur, car il existe de multiples façons d’interconnecter les processeurs. L’architecture influe sur la structure des algorithmes et des programmes à implanter.
3.1.2. Processeur multi-coeur
C’est un processeur capable de suivre plusieurs fils d’exécutions en même temps. Pour cela, il dispose de plusieurs unités de traitement appelées coeurs possèdant chacun une file d’instructions à exécuter, un compteur ordinal, des registres, une ALU, etc.
dmidecode donne des éléments sur le matériel$ dmidecode
...
Processor Information
Socket Designation: CPU1
Type: Central Processor
Family: Opteron 6200
Version: AMD Opteron(TM) Processor 6276
Voltage: 1.0 V
External Clock: 3200 MHz
Max Speed: 3600 MHz
Current Speed: 2300 MHz
Core Count: 16
Core Enabled: 16
Thread Count: 16
...
Processor Information
Socket Designation: CPU2
Type: Central Processor
Family: Opteron 6200
Version: AMD Opteron(TM) Processor 6276
Voltage: 1.0 V
External Clock: 3200 MHz
Max Speed: 3600 MHz
Current Speed: 2300 MHz
Core Count: 16
Core Enabled: 16
Thread Count: 16
...
lscpu donne des informations sur les processeurs$ lscpu Architecture : x86_64 Mode(s) opératoire(s) des processeurs : 32-bit, 64-bit Boutisme : Little Endian Tailles des adresses: 39 bits physical, 48 bits virtual Processeur(s) : 4 Liste de processeur(s) en ligne : 0-3 Thread(s) par cœur : 1 Cœur(s) par socket : 4 ...
3.1.3. Architecture vectorielle
C’est un exemple d’architecture parallèle, historiquement la première. Cette architecture permet d’exécuter une même opération simple (addition, multiplication, etc.) à un ensemble de données (vecteur, matrice, etc.). L’opération est effectuée en un seul cycle d’horloge sur la structure de données. Les calculs effectués sur les données sont identiques et indépendants les uns des autres. Concrètement, dans le code, les boucles sont remplacées par des instructions vectorielles :
-
si U=(u1,u2,u3) et V=(v1,v2,v3), alors l’addition vectorielle
W=U+Vremplace :
for i in range(1,4):
W[i] = U[i]+V[i]-
si M1 et M2 sont 2 matrices, alors
M3=M1+M2remplace :
for i in range(1,4):
for j in range(1,4):
M3[i,j] = M1[i,j]+M2[i,j]Les instructions vectorielles s’exécutent en parallèle sur les composantes du vecteur ou de la matrice (data parallelism). Le code devient plus simple et plus clair.
3.2. Programme parallèle
C’est un programme conçu pour tirer partie des capacités d’une architecture parallèle. Par exemple, le calcul d’une intégrale sur un intervalle peut être décomposé en la somme de n intégrales sur n sous-intervalles. Le résultat final est la somme des n résultats. Ces n calculs étant indépendants, ils peuvent être menés de front, ce qui divise théoriquement par n le temps de calcul.
3.3. Parallélisation
Mais dans le cas général, qui ne se réduit pas à appliquer une opération élémentaire à un groupe de données, c’est plus compliqué. Les programmes destinés à être exécutés sur une architecture parallèle doivent être conçus pour ce type d’architecture. Les algorithmes doivent être parallélisés : soit en développant des algorithmes spécifiques (par exemple map-reduce), soit en décomposant le problème à traiter, par exemple en agissant :
-
sur les données, en les regroupant de façon à pouvoir appliquer simultanément un même traitement à chaque groupe de données (cas du calcul vectoriel, ou plus généralement du data parallelism),
-
sur les traitements, en les découpant de façon à pouvoir les appliquer simultanément à un même ensemble de données (task parallelism).
|
La parallélisation ne doit pas être utilisée pour palier les faiblesses d’un algorithme : les gains de performances envisageables en améliorant un algorithme non parallèle peuvent être sans commune mesure à ce que l’on peut espérer en parallélisant un algorithme médiocre. |
Paralléliser un code demande d’examiner les dépendances entres les instructions qui le compose :
c = a+b
d = 2*cIci, ces 2 instructions ne sont pas indépendantes, elles ne peuvent pas être parallèlisées :
c doit d’abord être calculé pour pouvoir calculer d.
c = a+b
d = 2*b
e = a+eIci, pas de dépendance entre ces 3 instructions, elles peuvent être exécutées en parallèle, par exemple sur 3 unités de traitement différentes.
4. Concurrence
4.1. Multi-tâche vs parallélisme
Des traitements concurrents sont des traitements susceptibles de se superposer dans le temps. C’est donc du multi-tâche, mais pas forcément parallèle : les tâches peuvent s’exécuter sur un seul CPU, par morceau, en s’entrelaçant. Si elles sont asynchrones, alors elles évoluent chacune à leur rythme, sans ralentir ou stresser les autres : elles peuvent attendre des résultats ou des données sans bloquer les autres.


4.2. Contraintes
Les performances d’un programme peuvent être tributaires du CPU ou bien des entrées/sorties (E/S).
Un programme limité par le CPU (CPU bound) est un programme qui serait plus rapide si les CPU étaient plus nombreux ou plus rapides. Cela signifie simplement qu’il passe la majorité de son temps à faire des calculs. C’est le cas des programmes de calcul scientifique qui moulinent sans parler au réseau ou au système de fichiers (par exemple un programme calculant les décimales de π).
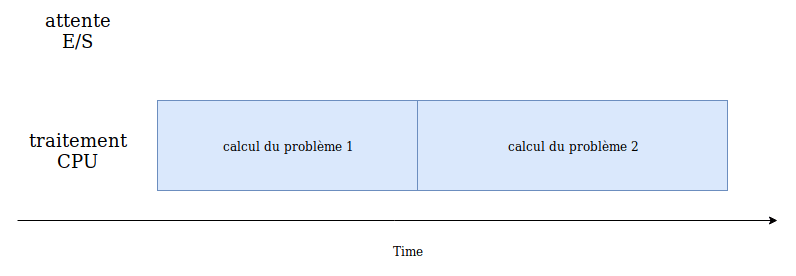
Ses performances ne dépendant donc que des CPU, l’accélérer consiste à lui donner plus de puissance de calcul.
Un programme limité par les E/S est un programme dont la progression est limitée par la vitesse des E/S (disque, réseau). Cela concerne donc les programmes échangeant des données avec l’environnement extérieur (ceux qui coopérent avec des services beaucoup plus lents que les CPU, comme les disques, le réseau, les bases de données, etc.).
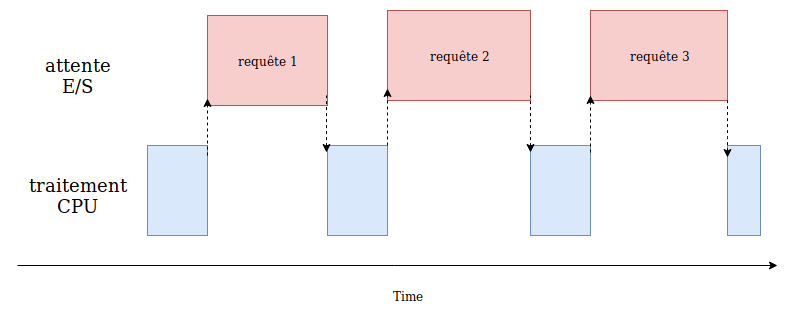
Accélerer un tel programme consiste à réduire les temps d’attente.
4.3. L’asynchronisme
Il y a des programmes qui passent leur temps à attendre, mais qui n’ont rien d’autre à faire. C’est le cas des applications interactives, comme le shell (en mode interactif) ou le navigateur web (il y a des navigateurs qui font des choses dans le dos de l’utilisateur, justement pendant les moments libres). Il y en a d’autres (I/O bound) qui auraient bien des choses à faire en attendant : il est dommage qu’un web scraping passe son temps à attendre la réponse d’un serveur sans rien faire, alors qu’il pourrait pendant ce temps en solliciter d’autres ou bien traiter les données déjà récoltées.
|
Analogie
Les vidanges chez le garagiste
|
Organiser une application en tâches asynchrones est essentiel si l’application possède des activités pouvant être ralenties ou bloquées (comme par exemple accéder à des ressources web). Une telle organisation permet d’éviter que l’application reste bloquée à ne rien faire, alors qu’elle pourrait traiter d’autres tâches qui ne dépendent pas de la ressource bloquante, en attendant que la situation se débloque.
Implémenter des tâches asynchrones, dans un programme, est un moyen de réduire le temps passé à ne rien faire. Dans cette approche, l’application optimise le temps total d’exécution en entrelaçant les instructions composant chacune des tâches, de façon à minimiser les temps d’attente. L’entrelacement des instructions vise à une progression harmonieuse de toutes les tâches.
La programmation asynchrone permet de mener de front des traitements ayant des cadences différentes, chaque tâche avançant à son rythme (en espérant qu’elles se termineront toutes à peu près en même temps).
4.4. Coroutine
Une coroutine ressemble à une fonction (routine) : une suite d’instructions empaquetée et appelable. La différence se situe à l’exécution. L’appel d’une fonction génère une tâche qui s’exécute sans interruption programmée, jusqu’à la dernière instruction et renvoie un résultat à l’appelant. L’appel d’une coroutine, quant à elle, génère une tâche susceptible de s’exécuter par partie.
L’exécution entrelacée d’un ensemble de coroutines est supervisée par un gestionnaire (appelé scheduler ou boucle d’évènements) agissant comme un chef d’orchestre.
4.5. Modèle producteur-consommateur
Le modèle producteur-consommateur est un modèle algorithmique adapté à un contexte asynchrone. Il modélise 2 types de tâche qui partagent une file d’attente :
-
des producteurs, qui produisent les données et les entreposent dans la file d’attente,
-
des consommateurs qui vont piocher leurs données dans la file précédente.
Ces tâches ne sont pas indépendantes, et des synchronisations doivent être ponctuellement mises en place :
-
les producteurs doivent s’assurer que la file peut accueillir leurs données (sinon ils doivent attendre que la file se vide suffisamment),
-
les consommateurs doivent s’assurer que la file contient assez de données à traiter (sinon ils doivent attendre que les données arrivent).