Lecture/écriture de données
1. Données textuelles
1.1. Format texte
Des données sont textuelles si elles sont humainement lisibles, c’est-à-dire si elles se visualisent comme une suite de caractères.
Par exemple, le format texte brut (plain text ) contient une suite de caractères. Un document au format texte brut représente un contenu basique, sans mise en forme ni structure. Il peut être affiché de multiples façons. Exemple :
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor, dignissim sit amet, adipiscing nec, ultricies sed, dolor. Cras elementum ultrices diam. Maecenas ligula massa, varius a, semper congue, euismod non, mi.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspen disse lectus tortor, dignissim sit amet , adipiscing nec, ultricies sed, dolor. Cras elementum ultrices diam. Maecenas ligula massa, varius a, semper congue , euismod non, mi.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed non risus. Suspendisse lectus tortor, dignissim sit amet, adipiscing nec, ultricies sed, dolor. Cras elementum ultrices diam. Maecenas ligula massa, varius a, semper congue, euismod non, mi.
Si le texte contient des méta-données pour le mettre en forme, ajouter de l’information (des notes, des renvois, etc.), ou le structurer, alors ce n’est plus du texte brut. Il est toujours humainement lisible, mais son interprétation n’est plus aussi immédiate :
<html><head>
<title>Lorem ipsum dolor sit amet, consectetur adipiscing elit.</title>
<body>Sed non risus. Suspendisse lectus tortor, dignissim sit amet,
adipiscing nec, ultricies sed, dolor. Cras elementum ultrices diam.
Maecenas ligula massa, varius a, semper congue, euismod non,
mi.</body></html>; Last modified 15 July 2010 by Juan Dona
[owner]
name=juan dona
organization=cablage ideal
[database]
; use IP address in case network name resolution is not working
server=192.0.2.42
port=143
file = "acme payroll.dat"{
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}A l’extrême, une donnée textuelle peut être humainement incompréhensible, bien que toujours humainement lisible. Le format est ouvert si la façon d’interpréter les données est connue, publique, normalisée. Par exemple, HTML est un format ouvert. Dans le cas contraire, le format est fermé (ou opaque). Il est utilisable seulement par les logiciels qui savent l’interpréter.
1.2. Fichier texte
Un fichier est une suite d’octets. S’il s’agit d’un texte en anglais, alors chaque octet est un caractère. Sinon c’est plus compliqué.
f=open(file=filename, mode="r")
ouvre un fichier texte en lecture,
opération obligatoire avant de pouvoir accéder à son contenu.
La valeur par défaut de mode étant r, on peut donc écrire simplement f=open(filename).
f est un objet qui contient divers attributs nécessaires à la gestion efficace de ce fichier :
la position courante dans le fichier,
un tampon (buffer) pour optimiser les transferts,
ainsi que divers indicateurs
(le fichier est-il ouvert ou fermé, est-il en erreur, etc.).
f=open(file=filename, mode="w")
ouvre un fichier texte en écriture.
Si le fichier existe déjà, il est vidé au préalable.
f=open(file=filename, mode="a")
ouvre un fichier texte en écriture.
Si le fichier existe déjà, le contenu qui lui est destiné est ajouté au contenu actuel.
f.close() ferme le fichier, et libère les ressources allouées par open,
c’est pourquoi il est important de ne pas l’oublier (sous peine de fuites mémoire).
Toutes les données écrites sont assurément dans le fichier après le close,
car le buffer est purgé à ce moment.
Sans close, rien n’est moins sûr.
1.2.1. Lecture d’un fichier texte
-
La méthode
readrenvoie n octets (tous par défaut) du fichier à partir de la position courante (et la position courante avance d’autant). -
La méthode
readlinerenvoie la ligne du fichier (et la ligne suivante devient la ligne courante).
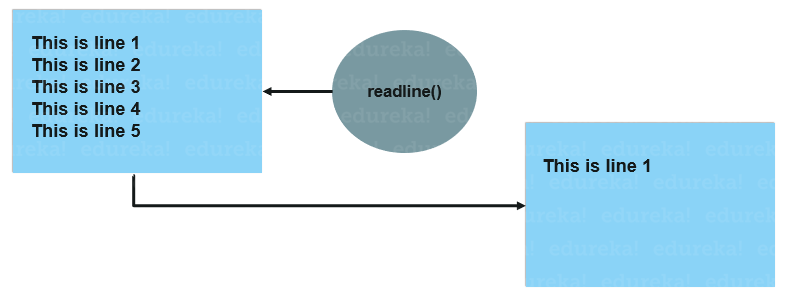
-
La méthode
readlinesrenvoie n lignes du fichier (toutes par défaut) à partir de la position courante (et la position courante avant d’autant).
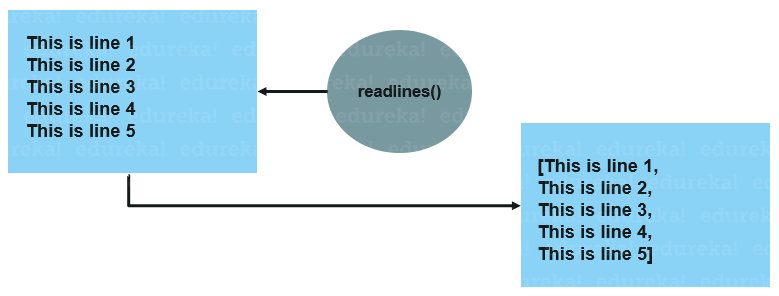
| Lorsque que le développeur demande à lire n caractères, en réalité un bloc de données complet est chargé depuis le disque vers la mémoire (dans le buffer), qui est ensuite exploité au fur et à mesure des demandes. Le système anticipe donc les demandes : il est plus performant de lire un bloc de données contigues sur le disque d’un seul coup, plutôt que de s’y reprendre à plusieurs reprises. |
Exemple de lecture ligne par ligne d’un fichier :
il=0
f=open("/etc/passwd","r")
for line in f.readlines(): (1)
il += 1
print(f"{il:03d}: {line}", end="")
f.close()| 1 | parcours d’une liste |
Cette version charge tout le contenu du fichier en mémoire. Pour éviter cela, mieux vaut écrire :
il = 0
f=open("/etc/passwd","r")
for line in f: (1)
il += 1
print(f"{il:03d}: {line}", end="")
f.close()| 1 | récupère line via un itérateur |
car ici c’est un itérateur qui renvoie successivement chaque ligne, On ne charge pas l’intégralité des données en mémoire, donc on peut traiter des fichiers plus volumineux que la mémoire disponible.
Une version équivalente en plus compact :
il = 0
with open("/etc/passwd","r") as f:
for line in f:
il += 1
print(f"{il:03d}: {line}", end="")
(1)| 1 | ici (à la sortie du with), le close est réalisé automatiquement. |
Dans toutes ces versions, le saut de ligne est mémorisé dans line, d’où le end="".
Et attention aux spécificités de chaque OS :
sous Unix, la marque de fin de ligne est \n, sous Windows c’est \r\n.
|
Pour lire un fichier caractère par caractère :
ic = 0
with open("/etc/passwd","r") as f:
while True:
if ic%40==0:
print(f"\n{ic:06d}: ", end="")
c = f.read(1) (1)
if not c:
break
print(f"{c if c.isprintable() else '■'}", end="")
ic += 1| 1 | lecture d’un caractère |
1.2.2. Ecriture d’un fichier texte
l = [ "un\n", "deux\n", "trois\n", "quatre\n" ]
f=open("/tmp/test","w")
f.writelines(l)
f.close()l = [ "un", "deux", "trois", "quatre" ]
f=open("/tmp/test","w")
for line in l:
print(line, file=f) # ou bien : f.write(line+"\n")
f.close()l = [ "un", "deux", "trois", "quatre" ]
with open("/tmp/test","w") as f:
for line in l:
print(line, file=f) # ou bien : f.write(line+"\n")print(line, file=f, flush=True)
écrit la ligne dans le fichier f, puis
force l’écriture immédiate du buffer sur le support physique.
1.3. Données sur le web
La ressource issue du web est récupérée intégralement en une requête. Elle peut ensuite être parcourue de différentes façons.
import urllib.request
url = 'https://math.univ-angers.fr/~jaclin/lorem.txt'
with urllib.request.urlopen(url) as response:
print(response.readlines())url = 'https://math.univ-angers.fr/~jaclin/lorem.txt'
il = 0
with urllib.request.urlopen(url) as response:
for line in response:
il += 1
print(f"{il:03d}: {line}")import urllib.request
url = 'https://math.univ-angers.fr/~jaclin/lorem.txt'
ic = 0
with urllib.request.urlopen(url) as response:
while True:
if ic%40==0:
print(f"\n{ic:06d}: ", end="")
c = response.read(1).decode() (1)
if not c:
break
print(f"{c if c.isprintable() else '■'}", end="")
ic += 1| 1 | read renvoie un byte, decode le transforme en caractère |
2. Données non textuelles
L’interprétation de fichiers images, vidéo ou audio, etc. est du ressort des programmes, pas des humains. Ce sont des données numériques. En mémoire vive, elles sont représentées sous forme binaire, performance oblige. Pour les enregistrer dans un fichier, le plus efficace consiste à recopier en bloc la mémoire sur disque. Mais dans ce cas, on obtient un fichier illisible par un humain sans super-pouvoir.
Pourtant, dans certains cas, on peut vouloir disposer d’un fichier de nombres lisible par un humain (sans super-pouvoir).
Ecrire un nombre dans un fichier texte suppose de le traduire en une suite de chiffres.
Par exemple, écrire l’entier représenté par les 4 octets 00 00 00 00
revient à écrire le caractère '0'
(puisque 00 00 00 00 est la représentation binaire de 0).
De même, écrire l’entier représenté par les 4 octets 255 255 255 255
consiste à écrire les 5 caractères '6', '5', '5', '3', '5'.
3. Fichier binaire
3.1. Exemple pour des entiers
with open("/tmp/f.bin", "wb") as f: (1)
for i in range(32768):
f.write(i.to_bytes(2,"little"))| 1 | noter le 'b' |
with open("/tmp/f.bin", "rb") as f:
while True:
i = f.read(2)
if len(i)<2: break
print(int.from_bytes(i,"little"), end=" ")3.2. Cas général
Les exemples précédents utilisent les méthodes from_bytes() et to_bytes() du type int .
Ils ne sont pas généralisables à d’autres types numériques.
Le module struct convertit les types numériques et au-delà,
dans des formats interopérables,
ce qui est indispensable pour lire des données binaires issues de tous horizons,
comme des données générées par de l’instrumentation (capteurs, séquenceurs du génome, etc.),
des programmes non Python, etc.
Soit l’exercice consistant à socker les termes de la suite de Fibonacci inférieurs à une certaine valeur dans un fichier binaire.
- Version 1
-
Pour l’écriture, on calcule un terme et on l’écrit dans la foulée :
import struct
last = 100000
a = b = 1
with open("/tmp/fib1.bin", "wb") as f:
f.write(struct.pack("i",a))
while (b<last):
f.write(struct.pack("i",b))
a,b = b,a+bPour la relecture, ne connaissant pas le nombre d’entiers dans le fichier, on récupérera les entiers un par un.
- Version 2
-
On calcule les termes et on les garde en mémoire. On écrit ensuite dans le fichier le nombre de termes, puis les termes eux-mêmes :
import struct
l = []
last = 100000
a = b = 1
l.append(a)
while (b<last):
l.append(b)
a,b = b,a+b
nb = len(l)
with open("/tmp/fib2.bin", "wb") as f:
f.write(struct.pack("i",nb))
f.write(struct.pack(f"{nb}i",*l))Connaissant le nombre d’entiers du fichier, on pourra les relire d’un seul coup.