Sérialisation
1. Persistance
Une donnée est persistante si son existence dépasse celle de l’application qui l’a créée. La donnée réside initialement en mémoire vive. Lorsque l’application se termine, elle disparait. Pour être persistante, elle doit donc être copiée sur un support non volatile, en attendant la prochaine exécution (qui la rechargera en mémoire vive).
Recopier la donnée ne se résume pas à recopier le bloc de mémoire correspondant. Lorsque la structure de la donnée est complexe, lorsque notamment il existe des liens entre différentes composantes de cette données, il faut alors trouver une représentation qui reste valide en dehors de son environnement natif.
| Par exemple, les relations entre les données utilisent souvent l’id, mais l’id perd son sens lorsque l’exécution se termine. |
La transposition de la donnée en un format valide au-delà de son contexte natif s’appelle sérialisation.
2. Sérialisation
La sérialisation (serialization, flattening ou encore marshalling) est le processus par lequel des données résidant en mémoire vive sont transformées (généralement en une suite d’octets) en vue de persister hors de ce contexte. Cette suite d’octets doit être suffisamment riche pour permettre de recréer la donnée à partir de rien (from scratch). L’opération réciproque (le décodage des informations pour créer une copie conforme à l’original) s’appelle la désérialisation (deserialization ou unmarshalling). Elle reforme l’objet en mémoire à partir d’une suite d’octets.
3. La méthode __repr__()
La méthode __repr__ est censée renvoyer une représentation complète de l’objet, qui doit permettre de le recréer from scratch dans un autre contexte.
Concrètement, c’est une fonction qui renvoie un bytearray ou une string caractérisant complètement l’objet.
Elle est à rapprocher de __str__(), mais __str__() est à destination des humains (développeur et utilisateur), alors que __repr__() est à destination des programmes.
Cette méthode existe par défaut (elle est utilisée en interne par python, notamment par la fonction repr()), mais peut être personnalisée par le développeur.
4. Exemple 1
Soit une class personnalisant sa méthode __repr__() :
class Point:
def __init__(self,x,y):
self.x = x
self.y = y
def __str__(self):
return f"({self.x},{self.y})"
def __repr__(self):
return f"{self.__class__.__name__}({self.x},{self.y})"A partir de là, on peut sérialiser le Point a :
a = Point(1,2)
print(a) # (1,2)
s = repr(a)
print(s) # Point(1,2)
# ... et sauvegarder s sur support non volatilepuis, dans un autre contexte, créer un clone b par désérialisation :
# recharger s depuis le support non volatile, puis...
b = eval(s)
print(type(b)) # <class '__main__.Point'>
print(b) # (1,2)
print(repr(b)) # Point(1,2)5. Exemple 2
On veut sérialiser une liste :
l1 = [ 1, 2, 1, 2 ]
s = repr(l)
...
l2 = eval(s)Cela fonctionne pour ce cas simple, mais qu’en est-il dans le cas général ?
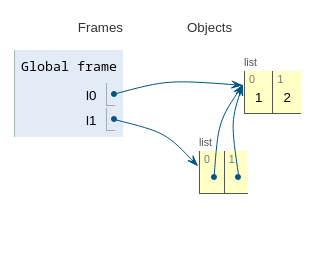
l0 = [1,2]
l1 = [l0,l0]
print(f"{l1[0] is l1[1]=}") # True
# serialisation
s = repr(l1) # '[[1, 2], [1, 2]]'
# ... sauvegarde de s sur support non volatile
...
# recharge de s depuis le support non volatile, puis...
# désérialisation
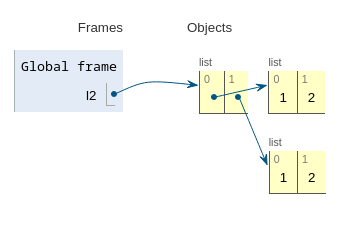
l2 = eval(s) # '[[1, 2], [1, 2]]'
print(f"{type(l2)=}, {l2=}") # <class 'list'> [[1, 2], [1, 2]]
print(f"{l1[0] is l1[1]=}") # FalseOn constate que l2 n’est pas un clone de l1 :
la sérialisation n’est pas correcte.
6. Le module Pickle
Ce module standard est spécialisé dans la sérialisation/désérialisation.
import pickle
class Point:
def __init__(self,x,y):
self.x = x
self.y = y
if __name__=="__main__":
l = []
for i in range(10):
l.append(Point(i,i))
with open("/tmp/picklefile","wb") as f:
pickle.dump(l,f)
Le format des données contenues dans /tmp/picklefile est spécifique à Pickle.
Par conséquent, l’application qui sérialise et celle qui désérialise
doivent utiliser Pickle (et attention si la version de Pickle est différente !).
ce qui sous-entend que ce sont 2 applications Python,
Pour lever cette contrainte, il faudrait utiliser un format plus portable,
un format ouvert indépendant, comme XML ou JSON.
|