Charset & encoding
1. Introduction
Un texte est composé de signes typographiques (les lettres) issus d’un alphabet. En informatique, on parle de caractères et de jeu de caractères (charset). Chaque caractère d’un charset est associé à un entier qui l’identifie. La correspondance caractère ↔ code entier pour l’ensemble des caractères du jeu s’appele un encodage (encoding).
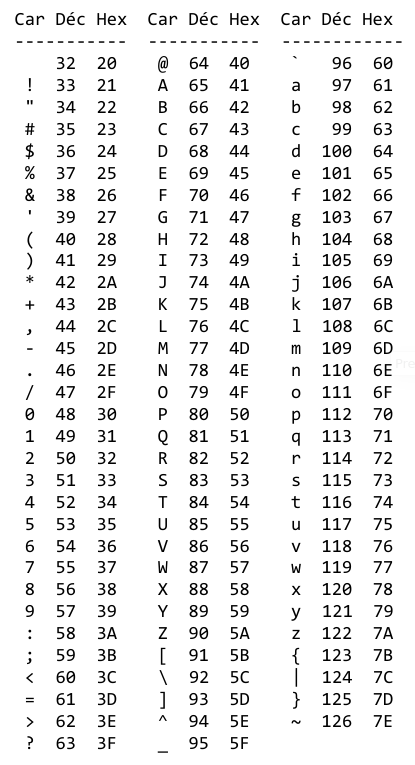
La liste ci-dessous représente les caractères imprimables de l’ASCII (American Standard Code for Information Interchange) et leurs codes (un entier compris entre 32 et 126).
2. Restrospective
2.1. Années 60 : début de l’ère informatique aux US
Les premiers ordinateurs sont apparus aux US.
L’alphabet de la langue anglaise comporte peu de lettres (26).
Le nombre de caractères nécessaires pour rédiger un texte
(minuscules, majuscules, chiffres, ponctuation et caractères particuliers, comme +, -, *, $)
ne dépasse pas 90.
7 bits sont donc suffisants pour les encoder,
ce qui laisse même de la place pour insérer de l’information supplémentaire :
des fonctions, appelées caractères de contrôle.
Ils correspondent aux codes compris entre 0 et 31, ainsi que 127.
Par exemple, le caractère :
-
8 (
x08) est le retour arrière (backspace,'\b'), -
9 (
x09) est la tabulation (tab,'\t'), -
10 (
x0A) est le saut de ligne (line feed,'\n'), -
13 (
x0D) est le retour chariot (carriage return,'\r') -
le 127 (
x7F) est l’effacement (delete).
Au final, cet ensemble de 128 caractères (caractères au sens large), connu sous le nom d’ASCII, est le premier jeu de caractères de l’ère numérique.
Chaque caractère est stocké sous forme d’un octet dont le bit de poids fort est 0 (ce bit unitilisé dans le codage sera utilisé comme bit de parité dans les transferts de données à cette époque où les communications ne sont pas super fiables).
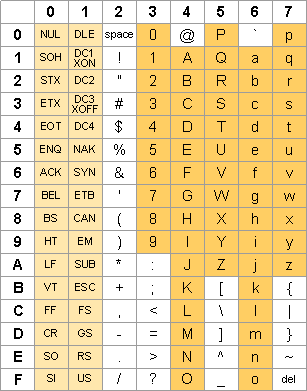
La table se lit colonne par colonne.
L’encodage est simple :
chaque caractère est codé avec la valeur de son indice dans la table.
Par exemple le code de 'A' est x41, soit 65 en décimal.
Le code du dernier caractère est x7F, soit 255 en décimal.
La fonction Python chr() donne un caractère à partir de son code,
et inversement, la fonction ord() fournit le code d’un caractère :
chr(0x30) # '0'
chr(0x7e) # '~'
ord('0') # 48
ord('~') # 126
f"{ord('0'):2X}" # '30'
f"{ord('~'):2X}" # '7E'Cet encodage ASCII reste fondamental même encore aujourd’hui, car la plupart des autres encodages n’en sont que des extensions. Ce qui veut dire par exemple que A est le caractère codé 65 dans la plupart des encodages utilisés aujourd’hui.
2.2. Années 80 : les langues nationales s’expriment
Pouvoir utiliser d’autres alphabets est revendiqué par les populations non anglophones. Pour y répondre, une idée consiste à utiliser la place libre de la table ASCII. Cela permet de la compléter avec 128 nouveaux caractères, tout en conservant un encodage sur 8 bits. L’avantage de cette idée c’est son faible impact au niveau logiciel, puisque la taille des codes reste inchangé. L’inconvénient est que 128 nouveaux caractères, c’est très insuffisant pour représenter tous les caractères de tous les alphabets.
Des charsets nationaux (ou pages de codes) sont donc déclinés. On trouve en particulier les charsets ISO-8859 :
-
ISO 8859-1, appelé aussi latin-1, l’alphabet de la plupart des langues d’Afrique sub-sahararienne et d’Europe occidentale,
-
ISO 8859-2 (latin-2, pour l’Europe centrale)
-
ISO 8859-10 et ISO-8859-13 (respectivement latin-6 et latin-7, pour les pays scandinaves),
-
ISO 8859-5 (Cyrillic),
-
ISO 8859-6 (Arabic),
-
ISO 8859-15 (une mise-à-jour de l’ISO 8859-1).
Des marques créent leur propres charsets :
-
CP1252, créé par Microsoft, pour Windows,
-
MacRoman, créé par Apple, pour MacOS.
Tous ces charsets utilisent un encodage sur 8 bits, disposent donc de 256 caractères, et englobent l’ASCII. Le principe de l’encodage, sur 1 octet, reste inchangé : chaque caractère est codé avec la valeur de son indice dans la table.
Ces charsets sont exclusifs : on ne peut en utiliser qu’un seul à la fois. Par exemple, on ne peut pas rédiger un texte français contenant une citation russe en cyrillique.
2.2.1. Autres alphabets
D’autres charsets de plus de 256 caractères voient également le jour, comme par exemple :
-
EUC-JP, pour les textes japonais, dont les caractères sont encodés sur 2 octets,
-
Big5, utilisé pour exprimer le chinois traditionnel à Taïwan, dont les codes sont sur 1 ou 2 octets, suivant les caractères.
| Changer la taille des codes a un impact colossal non seulement sur toutes les applications, mais aussi sur les langages de programmation, les compilateurs, les bibliothèques et même sur les systèmes d’exploitation : c’est une rupture technologique. C’est pourquoi, le principe des caractères codés sur 1 octet a été exploité aussi longtemps que possible. |
2.2.2. Conclusion
Les charsets nationaux et propriétaires ont été utilisés pendant plus de 20 ans. Mais ce principe a atteint ses limites, car il ne permet pas d’écrire des documents composites mêlant plusieurs alphabets. Mal compris par l’utilisateur lambda, il peut conduire à la production de documents inexploitables.
Avec les réseaux, les échanges massifs de documents mettent le problème en évidence : l’utilisateur de base a bien du mal à comprendre pourquoi les caractères accentués ont été transformés dans le document qu’il a reçu en pièce jointe dans un mail envoyé depuis un Mac. Difficile à comprendre aussi pourquoi il ne doit pas coller une partie d’un texte qu’il a rédigé sur son Windows, dans le document de son collègue qui travaille sur Unix.
3. Python et l’encodage
Un codec (encodeur/décodeur) est un composant logiciel qui permet de passer d’un caractère à son code, et inversement.
Le module Python encodings contient un ensemble de codecs.
Chacun d’eux porte le nom du charset qu’il prend en charge.
Il y a beaucoup de charsets synonymes, comme ISO 8859-1 → latin-1.
encodings.aliases.aliases est un dictionnaire associant à chaque alias son nom canonique.
3.1. Le type bytes
Le type bytes représente une séquence d’octets.
Il est à rapproché du type str qui, lui, représente une séquence de caractères :
s = "ABC"
print(type(s)) # str
print([c for c in s]) # ['A', 'B', 'C']
b = b"ABC"
print(type(b)) # bytes
print([c for c in b]) # [65, 66, 67]Le type str dispose d’une méthode encode() renvoyant la chaîne d’octets (de type bytes)
produite par l’encodage spécifié :
s = "ABCéèê"
print(type(s)) # str
b = s.encode(encoding="iso8859-15")
print(type(b)) # bytes
print(b) # b'ABC\xe9\xe8\xea'
print([c for c in b]) # [65, 66, 67, 233, 232, 234]
b = s.encode(encoding="iso8859-6") # erreur
b = s.encode(encoding="iso8859-6", errors='replace') # b'ABC???'
print([c for c in b]) # okEt réciproquement, le type bytes dispose d’une méthode decode()
renvoyant la chaîne (de type str) produite par le décodage spécifié :
b = b"ABC\xE9\xE8\xEA"
print(type(b)) # bytes
s = b.decode(encoding="iso8859-15")
print(type(s)) # str
print(s) # ABCéèê
print([c for c in s]) # ['A, 'B', 'C', 'é', 'è', 'ê']
s = b.decode(encoding="iso8859-6") # ABCىوي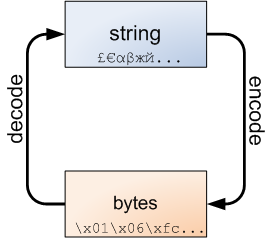
|
Les méthodes
|
|
Dans une string Python, on peut insérer littéralement des caractères, identifiés par leurs codes exprimés en hexa. Cela est particulièrement utile lorsque ces caractères n’existent pas sur le clavier, par exemple : ce qui donne : |
3.2. Entrées/sorties
Des opérations de codage/décodage ont lieu lorsqu’un qu’un texte change de support. Par exemple, un texte dans un fichier sur disque est encodé suivant un certain encodage. Un texte stocké dans une variable d’un programme est également encodé. Il n’y a aucune raison pour que ces 2 encodages soient les mêmes, Par conséquent, des transformations ont lieu à la lecture d’un fichier, et aussi à l’écritureI, qu’il est nécessaire de gérer correctement.
3.3. Questions pratiques
- Comment déterminer l’encodage d’un fichier ?
-
Dans le cas général, c’est-à-dire lorsqu’il n’y a pas de méta-données, il n’y a pas de méthode infaillible pour le déterminer. Il faut alors procéder par déduction :
-
une technique est de supposer un charset, et de voir ce que cela donne (c’est ce que permet par exemple http://string-functions.com/encodedecode.aspx)
-
les commandes Unix
xxd,file,iconvsont utiles -
on peut également lire le fichier comme une suite d’octets sans chercher à y faire correspondre des caractères, pour voir simplement ce qu’il y a dedans.
-
- Comment lire un fichier connaissant son encoding ?
-
Il suffit de spécifier l’encoding à l’ouverture du fichier :
fn = input("file name: ") with open(fn, "r", encoding="iso8859-1") as f: char = f.read(1) while char: print(f"{char}",end=" ") char = f.read(1)
- Comment lire un fichier ne connaissant pas son encoding ?
-
On peut toujours le lire octet par octet, pour voir :
fn = input("file name: ") with open(fn, "rb") as f: byte = f.read(1) while byte: print(f"{ord(byte):02x}",end=" ") byte = f.read(1)
- Comment écrire un fichier texte ?
-
Se poser d’abord la question : quel encodage utiliser pour mon fichier de sortie ?, puis ensuite :
with codecs.open("latin15.tab","w","ISO-8859-15") as f: print(s, file=f)
4. Conclusion
Pour exploiter des données textuelles stockées sur un support numérique depuis une application, il est nécessaire de connaitre sous quelle forme elles sont encodées sur le support externe. Symétriquement, le programme doit spécifier comment doivent être encodées les données textuelles qu’il génère.