Unicode (années 1990)
L’objectif d’Unicode est d’uniformiser le codage des signes typographiques de toutes les cultures (actuelles et passées), des symboles, smileys, etc., de pouvoir utiliser tous ces signes au sein d’un même texte, et d’obtenir des documents utilisables à l’identique sur tout système informatique.
Avec Unicode, un signe typographique est défini comme la plus petite composante d’un alphabet ayant une valeur sémantique. Par exemple, l’accent circonflexe est un signe, la cédille en est un autre. Unicode référence plus d’un million de signes.
| On les appellera, par habitude et par abus de langage, caractères, même si l’on voit bien la différence par rapport aux cas précédents. |
Chaque signe typographique est identifié par son code point, canonique et unique.
Il est noté U+xxxx, U+xxxxx ou U+xxxxxx, où x est un chiffre hexadécimal.
Exemple : U+0000 (le premier caractère), U+FFFF, U+10FFFF.
Plus que des alphabets, Unicode gère des écritures. En effet, chaque caractère Unicode possède des attributs : un nom et un code point, mais aussi des méta-données indiquant s’il s’agit d’une majuscule, d’une minuscule, d’un chiffre (et si oui, sa valeur) ou d’une ponctuation, s’il se combine à d’autres caractères (accent, cédille, etc.), son orientation (droite → gauche, haut → bas, etc.), etc.
|
La représentation graphique des caractères est un autre sujet, indépendant de la problématique de l’encodage. Un caractère peut se représenter graphiquement de différentes façons. Le dessin d’un caractère s’appelle glyphe, il est caractérisé par sa fonte, son corps, son style, sa graisse, etc. Un jeu de glyphes pour un alphabet donné s’appelle une police de caractères (par exemple Arial italique, Helvetica gras, etc.). Par exemple, a, a, a sont le même caractère a minuscule. De même pour : 
|
1. Encodages Unicode
Comme dans les charsets précédents, l’encodage détermine la représentation numérique d’un texte dans un environnement informatique donné. Mais la différence ici, c’est qu’Unicode en propose plusieurs. Par exemple, l’un deux, UTF-32, consiste simplement à encoder chaque caractère avec son code point. Mais cela n’est qu’un encodage parmi d’autres. Proposer plusieurs encodages permet de jouer sur 2 paramètres : la complexité de l’opération de codage/décodage et la taille des fichiers encodés.
| Le code point d’un caractère Unicode est son identifiant abstrait. Mais ce n’est pas nécessairement lui qui le représente dans sa forme numérique. Sa représentatation numérique est fixée par l’encodage utilisé. Unicode proposant plusieurs encodage, la représentation numérique de ses caractères n’est donc pas unique. |
Unicode est donc à la fois :
-
un charset (un jeu de caractères dont chacun possède un nom, un code point, et des attributs),
-
des encodages : UTF-8, UTF-16 et UTF-32.
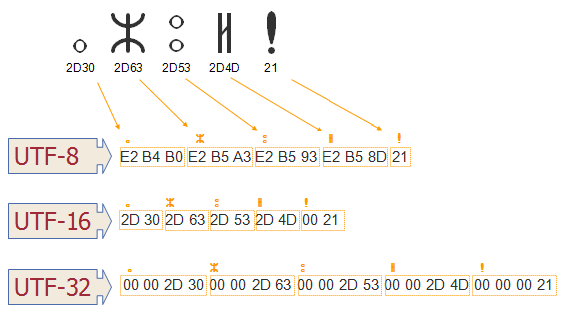
1.1. UTF-32
Chaque caractère est codé directement avec son code point sur 4 octets. Cette simplicité est son principal avantage : le codage/décodage est simple. Par contre, il est particulièrement gourmand en taille, et il est évidemment incompatible avec l’ASCII.
| S’il fallait encoder tous les caractères sur 4 octets, les fichiers deviendraient inutilement gros. En effet, la plupart des caractères sont entre 0 à FFFF (donc codables sur 2 octets), et, pour les caractères latins communs, la plupart sont même entre 0 et FF comme en ISO-8859-1 (donc codables sur 1 octet). |
1.2. UTF-16
La plupart des caractères, notamment ceux des langues modernes, y sont représentés sur 2 octets, les autres le sont sur 4 octets.
Il est plus économe en taille que UTF-32, et lui aussi incompatible avec l’ASCII. La longueur variable des codes complexifie les opérations de codage/décodage.
- Détail de l’encodage
-
-
Si la représentation binaire du code point du caractère ne dépasse pas 16 bits, alors il est codé sur 2 octets :
xxxxxxxx xxxxxxxx -
Sinon il est scindé en deux blocs de 10 bits répartis sur 4 octets de la façon suivante :
110110xx xxxxxxxx 110111xx xxxxxxxx
-
UTF-16 est utilisé dans l’environnement Windows (au travers de son API Unicode) et également par l’UEFI (une interface matériel/OS).
1.3. UTF-8
C’est l’encodage le plus utilisé en occident. Son codage de taille variable (entre 1 et 4 octets) lui permet d’être parcimonieux en taille pour les alphabets latin, au détriment de la vitesse de codage/décodage. Un autre avantage est sa compatibilité avec l’ASCII. Son inconvénient est la longueur variable de son codage, qui complexifie les traitements. Le principe est le suivant :
-
si le code point est inférieur à 128, le code est égal au point de code,
-
sinon, le code est une séquence de 2, 3 ou 4 octets, où chacun est compris entre 128 et 255.
Détail de l’encodage
-
Les caractères ASCII sont codés sur un octet dont le bit de poids fort est 0 :
0xxxxxxx -
Les caractères non-ASCII utilisent au moins deux octets :
-
le premier octet commence par autant de
1que d’octets dans la séquence, suivis par un0. -
les autres octets commencent par
10.
-
Ce qui donne :
-
code point ayant entre 8 à 11 bits :
110xxxxx 10xxxxxx -
code point ayant entre 12 à 16 bits :
1110xxxx 10xxxxxx 10xxxxxx -
code point ayant entre 17 à 21 bits :
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
2. Python 3 et Unicode
Un littéral Unicode est exprimé sous l’une des formes suivantes :
"\x41" # caractères ASCII
"\u0041" # la même chose
"\u0394" # caractères de code point de 2 octets en hexa (1)
"\U00000394" # caractères de code point de 4 octets en hexa(2)
"\N{GREEK CAPITAL LETTER DELTA}" # caractères Unicode exprimé avec son nom (3)| 1 | \u doit être suivi de 4 chiffres hexa |
| 2 | \U doit être suivi de 8 chiffres hexa |
| 3 | cf www.fileformat.info/info/unicode/char/0394 |
Le module unicodedata fournit un accès aux attributs Unicode :
import unicodedata
unicodedata.name('/')
unicodedata.lookup('solidus')
unicodedata.lookup('LEFT CURLY BRACKET')
unicodedata.category('A') # Letter uppercase
unicodedata.category('a') # Letter lowercase
unicodedata.category('9') # Numeric decimal
unicodedata.category('€') # Symbol currency
unicodedata.numeric('9')
unicodedata.numeric('a')3. Conclusion
Dans un monde futur idéal, Unicode règnera en maître, et tous les documents seront encodés avec l’un de ses encodages. Les logiciels, systèmes et environnements sauront les reconnaitre et les gérer. Il n’y aura alors plus de problème. En attendant, il faut faire avec l’existant, en indiquant explicitement l’encodage des textes que nos programmes lisent et écrivent.
Pour converger vers ce monde idéal, nous occidentaux, devons progressivement convertir nos fichiers en UTF-8 (c’est le plus raisonnable).